Hoe maken we data bruikbaar voor digital twinning? De wasmachine

In dit tweede deel van de blogreeks rond ons onderzoek 'The Organized Digital Factory' gaan we in op de manier hoe data die in verschillende formats binnen komt, naar een standaard wordt omgezet.
Het project “The Organized Digital Factory” (ODF) onderzoekt digital twinning voor mkb maakbedrijven die een hoge variëteit aan producten maken in lage volumes per product. Specifiek onderzoeken we hoe een digital twin van zo’n productieproces kan helpen bij een betere planning. Een planning die kortere doorlooptijden geeft en betrouwbaar is.
Wat is een digital twin
Een digital twin is iets in de echte wereld en een digitaal model hiervan (in dit geval dus het productieproces). Informatie uit de echte wereld wordt naar dit digitale model gestuurd en dit model kan hiermee simulaties en berekeningen uitvoeren. De resultaten van deze simulaties en berekeningen worden weer teruggestuurd naar de echte wereld. De onderstaande figuur geeft dit weer.
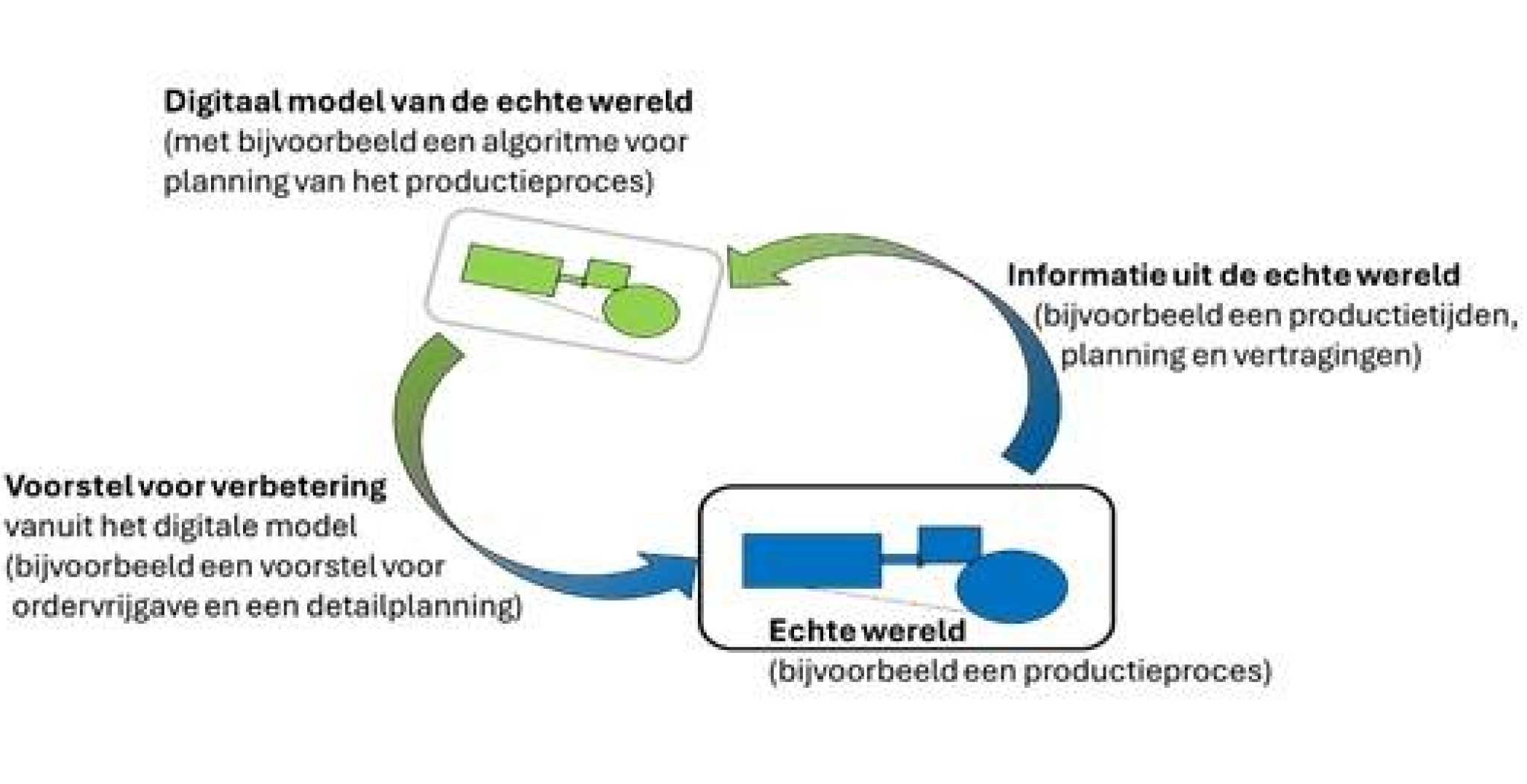
Productieprocessen in mkb-bedrijf
Bij het project ODF is de echte wereld: de productieprocessen van een mkb-bedrijf, en specifiek de productietijden van deze processen: de planning en de werkelijkheid. De digitale deel van de twin zijn dus de processen met de productietijden in digitale vorm, beschreven in algoritmes en modellen. Met deze algoritmes en modellen kunnen we naspelen wat de beste planning is, wat het effect is van een spoedopdracht, waar de bottlenecks zitten (en waar ze vanmiddag of morgen zitten).
Onze vorige blog vertelden we over de variatie die op het productieproces aankomt. Dit is de variatie van de klantvraag gecombineerd met de variatie in het productieproceszelf . En het blijkt dat deze twee vormen van variatie elkaar vaak tegenwerken. Onze twin algoritmes werken met deze variaties en onzekerheden en komen met een optimaal voorstel voor de planning.
Welke informatie krijgen we uit de echte wereld
Onze Digital Twins zijn bedoeld voor het plannen en controleren van de voortgang van de productie. Dat betekent dat we informatie uit de echte wereld moeten krijgen die te maken heeft met deze planning en voortgang. Dat is niet eenvoudig.
Als we kijken naar de input die we krijgen kunnen we dit weer te verdelen in de klantvraag én informatie over de planning en de voortgang. Laten we eerlijk zijn, er is geen bedrijf waarbij de informatie altijd correct is. En daarnaast, de vorm van de data over de planning verschilt van de klantvraag. En wat te denken van de informatie over de voortgang van de productie: Wanneer is een product klaar op een machine? Niet alle bedrijven houden dit goed bij, en zeker niet op dezelfde manier.
Je kunt je voorstellen dat alle informatie die we voor de twin binnenkrijgen van elkaar verschilt: verschil in format, verschil in timing (wanneer krijg ik het), verschil in naamgeving enzovoort. Dus voordat de data van klantvraag en de processen verwerkt kan worden, moet deze worden ‘geschoond’. Dit doen we door een paar slimme handelingen en uitgangspunten.
Ten eerste: we gebruiken niet alle data die er maar te vinden is, maar alleen de data die echt nodig is. We verzamelen dus niet de echte start en stoptijden bij de machine, maar downloaden deze uit een ERP systeem. En we voeren niet elke order apart in, maar de verzameling uit het ERP systeem, enzovoort. Voelt u hem aankomen? De eerste manier om de data op elkaar te laten lijken is de ERP ingevoerde data te gebruiken. Een nadeel hiervan is dat een ERP systeem niet altijd volledig klopt. Als we kijken naar de start- en stoptijden: de manier waarop dit in het systeem staat is natuurlijk afhankelijk van de manier van invoeren.
Wordt elke afgemaakte order direct afgemeld in ERP of worden de orders verzameld tot het einde van de dag of vlak voor de pauze. Wordt per order afgemeld of per product in de order? Of per machine of per werkcel met meer machines? En wat doe je met ordernummers die terugkeren elke week? En zo komen we veel varianten tegen, niet alleen over het afmelden van een proces, maar ook over invoer van orders, plannen, bottlenecks, routing, klantvraag, noem maar op.
Deze voorbeelden geven aan dat we nog iets moeten doen: de ERP data schoonmaken en zo gelijkmaken dat we het kunnen gebruiken bij twinning.

Dit doen we in de wasmachine
Dit is een innovatief software algoritme die we ontwikkelen om van de ruwe ERP data, mooie twin data te krijgen.
Wat betekent dit? Het klinkt eigenlijk heel simpel: We krijgen data in verschillende formats binnen en schakelen dat gelijk naar een format. Daarnaast, niet alles is bruikbaar, sommige data moet gecombineerd worden of juist uit elkaar getrokken. Kortom, voordat we een demand analyse kunnen doen of met proces mining het proces in kaart kunnen brengen, moet de data worden vertaald naar een standaard.
We hebben hard gewerkt om algoritmes te ontwerpen die de toegeleverde data vertalen naar een standaard dataformat. Zodat we gegevens uniform kunnen bewerken, analyseren en gebruiken voor planning en control.
Kortom: We hebben een “wasmachine” ontworpen waar ‘vuile’ data ingaat en ‘schone’ data uitkomt.
We kunnen nieuwe data (ook van andere bedrijven) in deze wasmachine stoppen en een demand analyse en proces mining analyse doen. Het vergt nog handmatig werken en tunen, maar de basis ligt er. Dit is een belangrijke stap in de ontwikkeling naar een standaard Digital Twin.
Wat komt eraan?
We werken verder aan de standaardisatie van de data. Een belangrijke output van het project zal de automatische wasmachine zijn die nieuwe data ( de klant vraag / demand en van de productieprocessen) inleest en deze automatisch (of zo automatisch mogelijk) omzet naar gestandaardiseerde data die door onze Twin kan worden verwerkt. De eerste tests binnen het project met de data van de deelnemende bedrijven zijn positief en we ontwikkelen verder: De wasmachine wast steeds beter schoon.
In volgende blogs vertellen over het automatisch in kaart brengen van de werkelijke voortgang van de productie (door procesmining), de planningsbeslissingen in de productie organisatie (en wat hier lastig aan is) en hoe we bottle necks in de productie kunnen detecteren (ook als die niet elke keer dezelfde machine is).
Blijf op de hoogte
Wilt u graag op de hoogte blijven van de ontwikkeling rond dit en ander actueel onderzoek?
Abonneer u dan op onze maandelijkse nieuwsbrief.
Lees voor meer informatie over dit specifieke onderzoek onderstaande blogs of neem voor meer informatie contact op met:
Menno Herkes, Menno.Herkes@han.nl

Lees ook de andere blogs uit deze reeks
Digital Twin als draaipunt
In de eerste blog 1 van onze reeks rond het onderzoek The Organized Digital Twin laat onderzoeker Menno Herkes zien hoe onze Digital Twin scharniert tussen vraag- en productievariatie en waarom dit ingewikkeld is.

Process mapping
In dit derde blog rond ons onderzoek 'The Organized Digital Factory' hebben we het over het in kaart brengen van de processen die we willen beheersen. Waarvoor dient de digital twin? Wie gebruikt de twin en hoe? En wat kan beter?
