Process mapping - Het in kaart brengen van processen die we willen beheersen

In dit derde blog rond ons onderzoek 'The Organized Digital Factory' hebben we het over het in kaart brengen van de processen die we willen beheersen. Waarvoor dient de digital twin? Wie gebruikt de twin en hoe? En wat kan beter?
Het project “The Organized Digital Factory” (ODF) onderzoekt digital twinning voor mkb maakbedrijven die een hoge variëteit aan producten maken in lage volumes per product. Specifiek onderzoeken we hoe een digital twin helpt bij een betere planning met betrouwbare en korte doorlooptijden.
Hiervoor is het belangrijk dat we de processen in kaart brengen die bij de planning horen. Hiermee kunnen we identificeren wie waarom de twin gebruikt en hoe de twin wordt ingezet. Dit is het onderwerp van dit blog: hoe hebben we voor onze twinning een procesmappingtechniek ontwikkeld.
Het is niet eenvoudig om voor een digital twin, een goede procesmap te maken. We willen niet alleen het productieproces bekijken en wat de planner hierbij doet. Maar het hele proces, van de verkoop van een product totdat het product af is, valt hieronder. En ook welke managementlagen meebeslissen, en wat er gebeurt bij wijzigingen in de planning en hoe regelen we de uitzonderingen.
Om deze processen in kaart te brengen bestaan verschillende methodes: voor elk doel is wel een geschikte methode te vinden. Echter, wij wilden één overkoepelend ‘plaatje’ hebben. Waar we alles wat we nodig hadden voor onze twinning konden plaatsen en analyseren. Daarover vertellen we hieronder.
Wat is een Digital Twin?
Laten we eerst terug gaan naar de twin en even herhalen: wat is een digital twin ook al weer. Een digital twin is iets in de echte wereld en een digitaal model hiervan (in ons geval dus het productieproces). Informatie uit de echte wereld wordt naar dit digitale model gestuurd en dit model kan hiermee simulaties en berekeningen uitvoeren. De resultaten van deze simulaties en berekeningen worden weer teruggestuurd naar de echte wereld. Het volgende plaatje geeft dit weer:
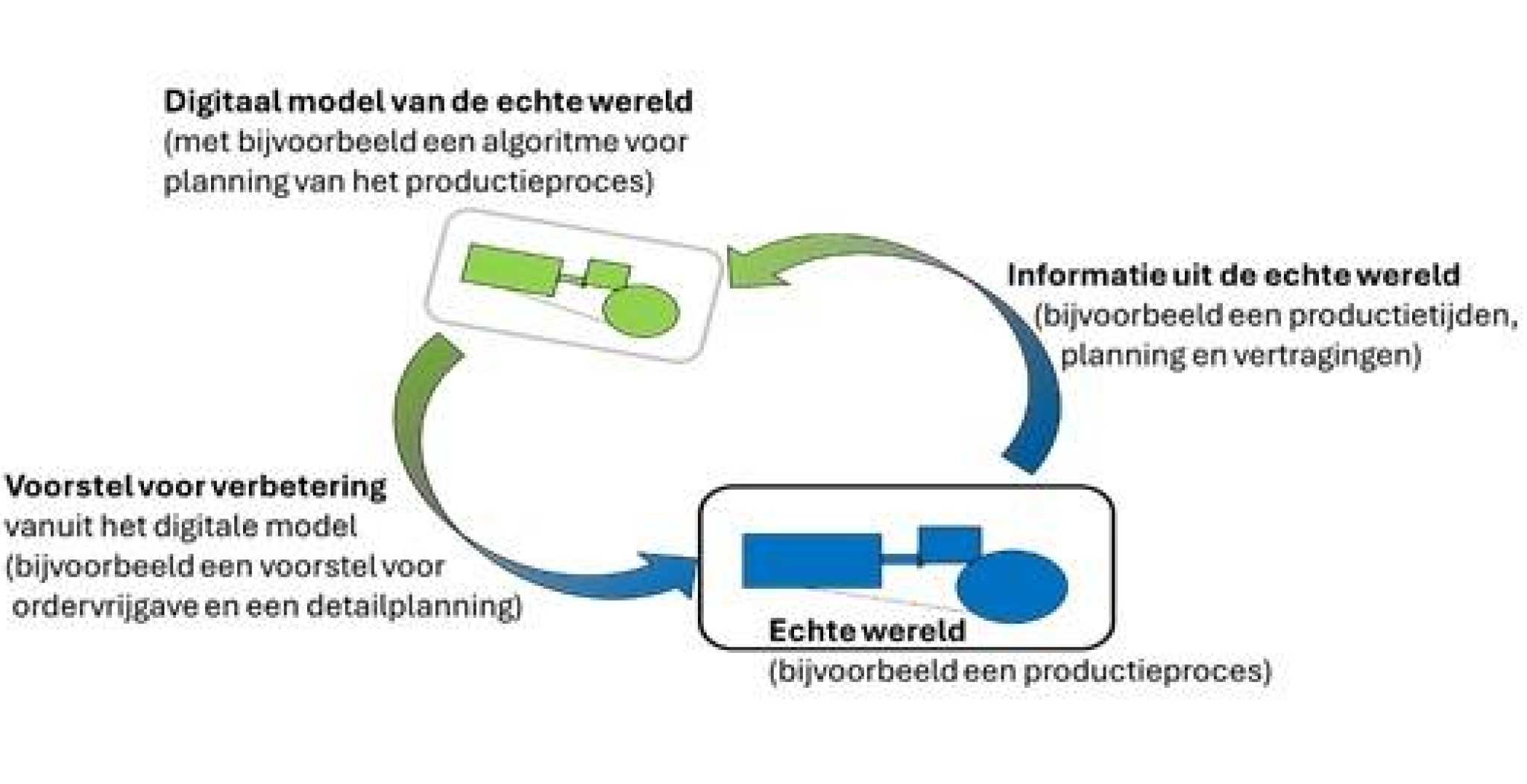
Bij het project ODF zijn de productieprocessen van een mkb-bedrijf de echte wereld en specifiek de productietijden van deze processen: de planning. Het digitale deel van de twin zijn deze processen met de productietijden in digitale vorm, beschreven in algoritmes en modellen. Hiermee kunnen we de beste planning simuleren. Wat is het effect van een spoedopdracht? Waar de bottlenecks zitten (en waar ze vanmiddag of morgen zitten)? Een soort google maps met routeplanner voor de productie, afhankelijk van de echte situatie op de weg, krijg je de optimale route te zien met alle mogelijkheden.
In onze vorige blogs vertelden we over de variatie die op het productieproces aankomt: De variatie van de klantvraag gecombineerd met de variatie in het productieproces zelf . Het tweede blog vertelde over de data input, hoe zorgen we dat we de goede gegeven uit de processen krijgen en deze ‘schoonmaken’ in onze data wasmachine.
In dit blog hebben we het over het in kaart brengen van de processen die we willen beheersen, waarvoor dient de twin? Wie gebruikt de twin en hoe? Wat kan beter?
Wat hebben we gedaan: eerste steady state model
Een veelgebruikte methode om productieprocessen in kaart te brengen is met een systeemschema via een “Steady State Model”. Eigenlijk is dit een weergave van een meet- en regellus van het productieproces. Hier bestaan verschillende soorten van en wij hebben gekozen voor de methode van In ’t Veld, omdat dit het beste aansluit bij de praktijk van productieprocessen. In het schema hiernaast is een eenvoudige versie van zo’n steady state weergegeven. De grote rechthoek onderin kan een machine zijn, een serie van machines of het hele proces. De metingen gaan bij onze digital twin over de start- en stoptijden van de productie. De vergelijking met de norm kijkt of deze tijden gelijk zijn aan de planning: is er een afwijking, dan grijpen we in met veranderingen in de ordervrijgave.

Het productieproces is hier een rechthoek, maar in de praktijk waren dit er natuurlijk meer: elke processtap, en soms elke machine heeft een eigen rechthoek met regelkring. Al deze regelkringen sluiten op elkaar aan en werken op elkaar in. Dat kan snel ingewikkeld worden zoals je in het scherma hiernaast ziet. Deze schemamethode was het startpunt om de productie en planning in kaart te brengen. Hiermee hebben we bij partnerbedrijven ook de beslissingsorganisatie (functies en verantwoordelijkheden) in kaart gebracht, het orderintake proces, de informatiestromen en informatiesystemen. Hiervoor hebben we logistieke schematechnieken toegevoegd, informatie systeemsymbolen en technieken toegevoegd en zelf schematechnieken ontwikkeld.

Stukje bij beetje hebben we de steady state mapping uitgebreid totdat we een totaal overzicht hadden over alles waar de Twin mee te maken gaat krijgen.
In het volgende plaatje staat hier een voorbeeld van. Het is voor u niet te lezen, maar geeft een indruk van een totaalplaatje.
De blauwe rechthoeken staan de voorbereidende functies (verkoop, orderintake, engineering, planning en werkvoorbereiding etc.).
Het gele deel geeft het productieproces weer met alle deelprocessen, regelkringen en wie wat doet.
Dit schema geeft inzicht in de complexiteit van de productie en beslissingsprocessen (in het organisatie ontwerp) en de mogelijkheden om deze processen te vereenvoudigen en hiervoor een twin in te richten.
Waar gebruiken we deze process mapping voor?
De eerste stap:
Dit is het weergeven van de huidige situatie voor de ontwikkeling van de eerste twins. Uit de mapping blijkt wie de beslissingen nu nemen: Dus als we de twin gaan inzetten: wie gaat de output gebruiken. Dit is bepalend voor de algoritmes: een planner heeft andere real time informatie nodig dan de operations manager of de operator. Dit geeft ook richtlijnen voor de mens machine interface, welke informatie wordt getoond en hoe, wat is het gebruik van de twin.
De tweede stap:
Dit is de ontwikkeling naar de toekomst.
• Uit de mapping blijkt soms dat beslisprocessen over de planning op dit moment niet goed lopen of dat de werkelijkheid die wij gevonden hebben niet overeenkomt met de gewenste huidige situatie. Dit houdt in dat we in de nabije toekomst de twins moeten ‘herijken’ voor gebruik dat wel aansluit op de gewenste, huidige situatie.
• Daarnaast gebruiken we deze mapping om met de bedrijven in gesprek te gaan over de beslissings- en organisatiestructuur van de toekomst met de twin. Als je een goed werkend twin systeem hebt dat de bottleneck ver van tevoren herkent, snel wijzigingen doorrekent en een ideale ordervrijgave kan genereren: welke functies blijven bestaan en welke wijzigen of verdwijnen? Wil het bedrijf kiezen voor centraliseren van de planningsbeslissing, of juist decentraliseren. Beide opties kunnen.
Wie heeft welke kennis nodig om in de toekomst met de twin om te gaan? Waar zitten de verbetermogelijkheden om planprocessen te vereenvoudigen? Wat wijzigt in de hiërarchie?
In het verlengde hiervan: hoe gaat het productiebedrijf om met real time beslissingsinformatie?
Deze laatste discussie (op weg naar een nieuwe organisatie) is een lastige, maar wel de meest waardevolle. Bedenk dat alle innovatie effect heeft op de organisatie van je processen, maar deze effecten zijn erg groot bij het gebruik van overal beschikbare, real time informatie over de planning en besturing van je productieproces. De kern van je bestaan.
In ons ODF project, kunnen we niet de hele discussie doormaken. Dit onderzoek gaan we dan ook vervolgen met onderzoeken naar de organisatie en het gebruik van de twin. We bouwen hierop voort.
In een volgend blog gaan we in op geavanceerde bottlenneck detectie en zelfs voorspelling.
Blijf op de hoogte
Wilt u graag op de hoogte blijven van de ontwikkeling rond dit en ander actueel onderzoek?
Abonneer u dan op onze maandelijkse nieuwsbrief.
Lees voor meer informatie over dit specifieke onderzoek onderstaande blogs of neem voor meer informatie contact op met:
Menno Herkes, Menno.Herkes@han.nl

Lees ook de andere blogs uit deze reeks
Digital Twin als draaipunt
In de eerste blog 1 van onze reeks rond het onderzoek The Organized Digital Twin laat onderzoeker Menno Herkes zien hoe onze Digital Twin scharniert tussen vraag- en productievariatie en waarom dit ingewikkeld is.

Hoe maken we data bruikbaar voor digital twinning?
In deze tweede blog van de reeks rond ons onderzoek 'The Organized Digital Factory' gaan we in op de manier hoe data die in verschillende formats binnen komt, naar een standaard wordt omgezet.